데이터 사이언티스트는 AI나 예측모델을 개발하기 위해서 가장 먼저 프로젝트의 목적에 따른 데이터의 기본 상태를 파악하고, 이에 따른 예상 결과물을 결정한 후 작업 방식과 소요시간을 예측하고 최종적으로 확보된 데이터에 대한 적합성을 판단해야 한다.
초거대 AI를 활용한 프로젝트가 많아지면서 규모가 커지고 인원과 비용도 증가함에 따라 사전 탐색과정에서 판단이 잘못되었을 경우 발생하는 손실도 커지고 있다. 서비스가 운영되고 참여자가 활동해야만 발생하는 데이터의 경우 상당한 수집 시간이 필요하며, 외부에서 구입할 경우에도 비식별처리와 전처리에 오랜 시간이 소요되기 때문에 데이터에 대한 프로젝트 초기에 이루어지는 데이터 적합성 판단은 빠르고 정확해야만 한다.
데이터 탐색의 기본 단계
데이터를 탐색할 때는 기본적으로 품질과 양을 검수하는 과정부터 시작한다. 데이터에 있어서 품질이란 항목에 따라 입력 값이 제대로 채워져 있는지, 그리고 고객 또는 작업자가 규칙에 따라 정확하게 입력하였는지를 확인하는 과정이다.
캐글의 Data ScienceTutorial for Beginners의 데이터를 활용하여 하나씩 살펴보도록 하자. 해당 자료에는 데이터뿐 아니라 기본 탐색코드도 자세하게 나와있는 편이니 관심 있는 사람은 참고해도 좋다. 이 포스트는 참고 자료에서 가장 중요한 핵심코드를 단계별로 좀 더 자세하게 설명하였다.
1) 기본 구성과 규칙
기업이 제공하는 상품과 서비스를 통해 수집되는 데이터는 대부분 전산화된 환경에서 직원이 단말을 통해 입력하거나 고객이 직접 기입한 정보로 이루어져 있다. 로그의 경우에도 사용하는 솔루션이 정해진 규칙에 따라 에러코드나 메시지를 출력하며, 이미지와 텍스트 등의 비정형 자료라고 해도, 사용되는 단어와 해상도 등 환경에 따라 일정한 범위 내에서 데이터가 수집된다.
데이터 탐색의 가장 처음 단계는 이러한 규칙을 확인한 후 제대로 채워져 있는지 확인하는 작업으로 우선 솔루션이나 시스템 담당자가 제공하는 메타데이터를 읽어본 후 실제 데이터가 규칙에 맞는지 확인하는 과정이다.
우선 데이터(CSV파일)을 읽어온 후 맨 위 5줄의 값을 확인해 보자.
import pandas as pd #pandas라이브러리 호출
data = pd.read_csv('../input/pokemon.csv') #CSV파일 로딩
data.head() #윗 부분 데이터 보기(기본 5줄)
포켓몬의 속성에 대한 데이터라는 설명만 나와있었는데, 데이터를 보니 타입과 체력, 공격력 등으로 구분되어 있는 것을 짐작할 수 있다.

다음으로 Pandas라이브러리에 내장된 info함수를 이용하여 기본정보를 살펴보자.
data.info() #기본정보 보기총 12개의 컬럼으로 800개의 데이터를 가지고 있으며, 1개의 참/거짓(bool)값과 3개의 문자열(object), 그리고 8개의 숫자(int64)로 구성되어 있다.

주목해야 할 부분은 Name에 1개 값이 비어 있으며, Type 2는 414만 채워져 있어 필수 값은 아닌 것처럼 보인다.
2) 기초 통계
Pandas라이브러리는 각 컬럼의 통계를 쉽게 확인할 수 있는 describe함수를 제공한다.
data.describe()위와 같이 실행하면 널값(비어있는 값)을 제외한 수치값을 가진 컬럼의 평균과 편차, 그리고 분포를 확인할 수 있는 분위수를 하나의 표로 출력해준다.

기초통계에서 Speed컬럼의 값은 5~180인데 중앙값(50%)와 평균은 65, 68.27로 낮은 구간에 많이 치우쳐 있는 듯이 보인다. 이럴 때는 라이브러리에 포함된 plot함수를 이용해 간단하게 분포를 확인할 수 있다.
data.Speed.plot(kind='hist', bins=50)히스토그램(도수분포표)의 간격(bins)를 50으로 지정하고 출력하면 다음과 같은 그래프를 확인할 수 있다.

분포표를 확인해본 결과 Speed가 50대에 가장 많이 몰려있음을 알 수 있다.
컬럼간 상관관계
데이터간의 상관관계는 예측모델을 개발할 때 개발 가능성과 예상 성능을 가늠할 수 있게 해준다. 또한 간단한 인사이트는 상관관계만으로도 도출할 수 있다. 상관관계는 corr함수를 이용하여 간단하게 확인할 수 있다.
1) 상관계수
data.corr()
하나의 표로 정리되어 보이는 것은 좋지만, 숫자로만 표시되어 가독성이 떨어질 경우 PairPlot(여러 변수간 산점도)를 확인할 경우 좀더 쉽게 상관관계를 파악할 수 있다.
2) 여러 변수간 산점도
import seaborn as sns #차트 라이브러리 호출
sns.pairplot(data[['HP','Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation']])Seaborn차트 라이브러리를 호출한 후 수치값(int64)만 지정하여 PairPlot을 그리면 아래와 같은 차트를 얻을 수 있다.

대부분의 컬럼이 상관관계가 그리 높진 않지만 Sp.Atk과 Defense, 그리고 Speed가 서로 상관관계가 높은 것을 알 수 있다.
세부 탐색
기본적인 구성과 통계, 그리고 상관관계 등을 파악하고 나면 좀 더 상세하게 데이터를 쪼개어 확인하거나 가설을 검증해볼 필요가 있다.
1) 카테고리별 통계값
data.groupby("Generation").mean()groupby함수에 컬럼을 지정하면 카테고리별로 나뉘어진 데이터를 얻을 수 있다. 여기에 평균(mean)을 지정하면 아래와 같이 Generation별 평균값이 출력된다. 이를 응용하면 표준편차(std), 최소값(min), 최대값(max)도 쉽게 확인할 수 있다.
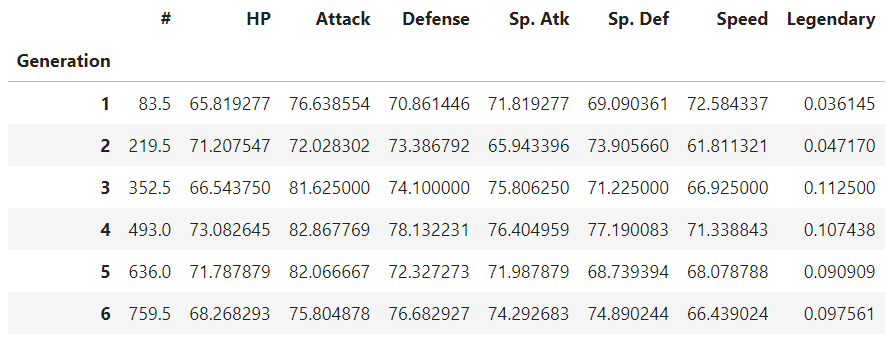
2) 특정값(범위)의 통계값
앞서 알아본 결과 speed의 평균값은 68.27이며 다들 수치들과도 상관관계가 높았던 것을 알 수 있다. 그렇다면 speed가 높을 수록 다른 수치도 높게 나타날까? 이러한 가설은 범위를 지정하여 간단하게 확인할 수 있다.
data[data.Speed <= 68].mean()대괄호안에 컬럼명과 조건을 넣어주면 원하는 범위를 지정할 수 있다. 평균보다 낮은 개체의 수치를 확인하기 위해 조건을 지정하고 실행한 결과 총 404개의 데이터가 걸러졌으며 각 컬럼별로 아래의 평균값이 표시되었다.
# 404.544811
HP 65.471698
Attack 68.504717
Defense 71.759434
Sp. Atk 60.775943
Sp. Def 64.832547
Speed 45.721698
Generation 3.398585
Legendary 0.009434
dtype: float64다시 평균보다 높은 개체를 걸러서 평균값을 확인해보자.
data[data.Speed > 68].mean()총 395개의 개체가 지정되었으며 Speed뿐 아니라 전반적으로 높은 수치를 가졌음을 알 수 있다.
# 395.938830
HP 73.529255
Attack 90.837766
Defense 76.191489
Sp. Atk 86.401596
Sp. Def 79.875000
Speed 93.712766
Generation 3.239362
Legendary 0.162234
dtype: float64
'세줄 코딩(실무용 알고리즘)' 카테고리의 다른 글
| 시계열 예측방식, 그리고 가장 간단한 시계열 예측 알고리즘 (102) | 2023.11.17 |
|---|---|
| 시계열 데이터를 간단하게 분석하는 방법 (99) | 2023.11.10 |
| 데이터 탐색이 모델 개발에서 가지는 의미(with 고인물) (93) | 2023.09.23 |
| AutoML(자동화 기계 학습)로 누구나 만들 수 있는 예측 모델 (89) | 2023.09.15 |
| 장바구니 분석(연관분석)의 구조와 활용 방법 (99) | 2023.09.09 |