확률로만 계산하는 연관분석
연관분석은 협업 필터링과 달리 유사도 기반 함수를 이용하지 않고 대상 품목의 빈도를 기반으로 확률을 계산하기 때문에 분석하기 쉽다는 장점을 가지고 있다.
그래서 엑셀이나 계산기로 분석할 수 있을 만큼 간단한 구조를 가지고 있지만, 품목별 연관관계뿐 아니라 2~3가지 품목이 조합된 세트의 연관관계까지 뽑아내려면 반복적으로 계산할 수 있는 프로그램을 이용해야 한다.
하지만 이 프로그램마저 구조가 간단해서 연재의 취지에 맞게 쉽게 활용 할 수 있지만, 이왕 쉬운 분석 방법을 만났으니 통계기반 알고리즘들이 어떠한 구조로 동작하는지 설명하면서 원리에 맞는 활용 방법을 설명해보고자 한다.
연관분석은 총 3가지의 빈도계산 방식을 가지고 있으며 각각 다른 의미를 가지고 있다.
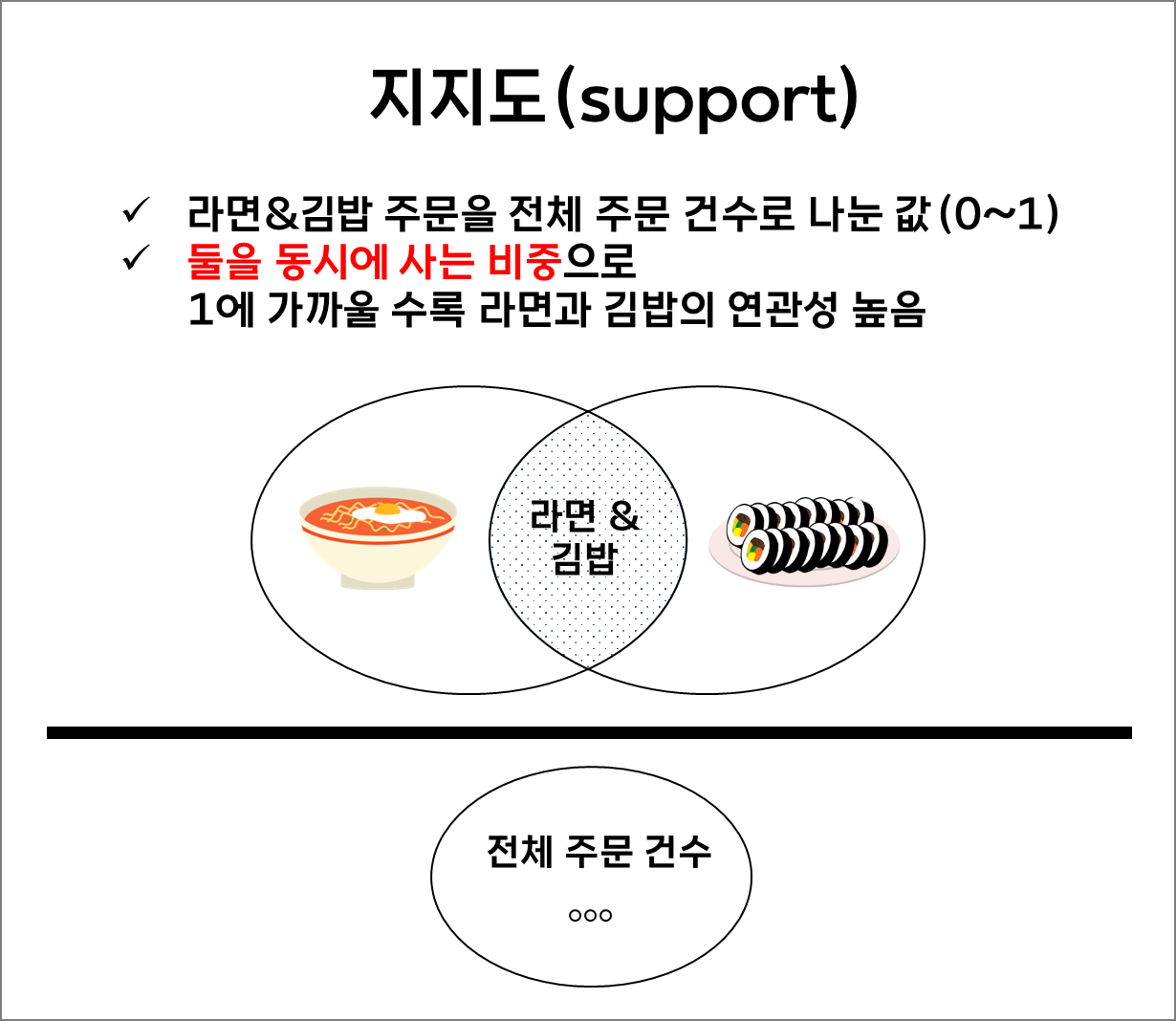
지지도(A&B 동시 구매 비중)
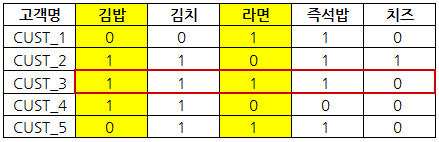
지지도는 연관상품이 같이 판매되는 비중으로 이전 협업필터링 설명 시 사용했던 편의점 구매데이터를 기준으로 라면과 김밥의 연관성을 설명하자면 전체 5건의 거래 중 라면을 기준으로 김밥을 같이 산 거래는 1건이므로 1/5로 0.2가 나온다. 지지도는 0~1의 값을 가지며 1에 가까운 갑을 가질수록 김밥과 라면의 연관성이 높다고 볼 수 있다.

신뢰도(A단독구매 대비 A&B 동시 구매 확률)
신뢰도는 라면을 샀을 때 김밥도 사는 비중으로 앞서 계산한 지지도를 라면 주문 계산한다. 앞서 계산한 지지도는 0.2이며 아래 데이터에서 전체에서 라면을 구매한 비중은 0.6(3/5)이니 0.2/0.6으로 0.33의 신뢰도를 가지게 된다. 신뢰도 또한 지지도와 마찬가지로 0~1의 값을 가지며 1에 가까울 수록 연관성이 높다.


향상도(B구매 확률 대비 A&B연관성의 강도)
향상도는 앞서 계산한 신뢰도를 연관성을 계산할 대상의 구매확률로 나눈 값으로 여기서는 김밥에 해당한다. 김밥의 구매건수는 3건으로 0.6(3/5)의 확률을 가지고 있으니 신뢰도 0.33을 0.6으로 나눈 0.55의 향상도를 가진다.
향상도는 1을 기준으로 작으면 우연보다 낮고 1보다 크면 우연보다 높은 관계로 해석하므로 라면과 김밥은 낮은 향상도를 가진다.

앞서 아마존의 상품기반 추천방식(협업필터링)에서도 라면 → 김밥은 높은 상관성을 가지지 않았고 김밥 → 김치가 높은 상관관계를 가지고 있었는데, 같은 방식으로 김밥 → 김치의 연관관계도 분석해보면 지지도 0.6(3/5), 신뢰도 1(0.6/0.6), 향상도 1.25(1/0.8)로 3개 수치에서 모두 높은 연관성을 가지는 것으로 나타난다.

연관 분석 방법 및 예시
지난 포스트에서 언급했듯이 연관분석은 2~3개의 세트 상품에 대한 연관성을 계산할 수 있다는 장점을 가지고 있으며 단일 품목에 대한 연관성은 협업필터링과 크게 다르지 않다.
그래서 연관분석 알고리즘들은 여러가지 상품으로 구성된 세트를 먼저 만든 후 이 세트의 연관성을 위에서 진행했던 방식으로 계산하게끔 프로그램되어 있다.

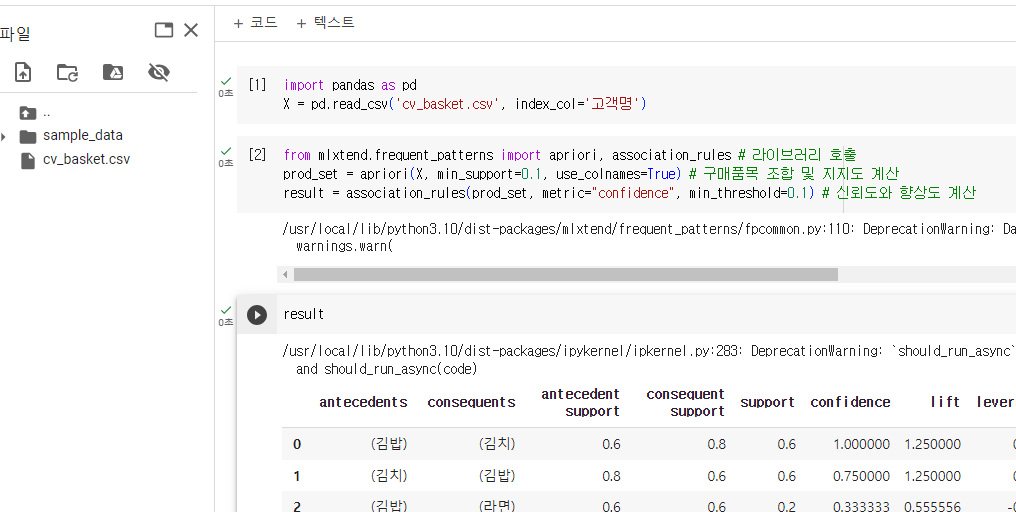
연관분석을 위한 파이썬 기본 코드는 아래와 같다.
from mlxtend.frequent_patterns import apriori, association_rules # 라이브러리 호출
prod_set = apriori(X, min_support=0.1, use_colnames=True) # 구매품목 조합 및 지지도 계산
result = association_rules(prod_set, metric="confidence", min_threshold=0.1) # 신뢰도와 향상도 계산첫번째줄에 연관분석 라이브러리를 호출하고, 두번째줄에서는 구매품목을 조합한 후 지지도를 계산한다. 그리고 마지막으로는 여기에 신뢰도와 향상도를 추가하여 결과를 저장한다.
앞서 예시로 들었던 편의점 데이터를 코랩에 업로드한 후 연관분석을 실행하면 다음과 같은 결과를 얻을 수 있으며, 결과는 총 88종의 상품 조합으로 위에서부터 지지도/신뢰도/향상도가 높은 순으로 정렬되어, 단일품목간의 조합과 여러 상품을 한꺼번에 구매했을 때의 수치가 표시되어있다.


앞서 협업필터링에서 가장 높았고, 수작업으로 계산했을 때도 높게 나왔던 김밥 → 김치가 가장 높은 연관관계를 가지는 것으로 표시되었으며, 그 다음은 김치를 샀을 때 김밥도 살 확률(김치 → 김밥)의 연관관계가 높게 나타나있다.
겨우 5개 품목에 5건의 구매기록만으로 이러한 다양한 조합이 분석될 정도로 연관분석은 다양한 경우의 수를 탐지하고 이를 연산하기 때문에 각 지표의 계산은 쉬운데 반해 총 연산량은 많은 편인데, 코드에서 2번째줄의 min_support와 3번째줄의 min_threshold의 숫자를 0.5이상으로 높여두면 결과파일은 줄여서 내려 받을 수 있다.
예시파일은 데이터가 적어 단일품목 중심으로만 높은 결과가 나왔지만, 실제 장바구니 분석에서는 2~3개의 품목 조합도 높은 연관관계를 가진 경우가 많기 때문에 앞서 말한대로 상품을 조합하여 진열하는데 상당히 유용하게 활용할 수 있다.
참고로 코랩에서 CSV파일을 업로드하고 결과를 복사한 코드 구성은 다음과 같다.
'세줄 코딩(실무용 알고리즘)' 카테고리의 다른 글
| 데이터 탐색이 모델 개발에서 가지는 의미(with 고인물) (93) | 2023.09.23 |
|---|---|
| AutoML(자동화 기계 학습)로 누구나 만들 수 있는 예측 모델 (89) | 2023.09.15 |
| 상품 추천 알고리즘 - 협업 필터링 vs. 연관분석 (89) | 2023.08.24 |
| 디시전트리(의사결정나무)로 쉽고 정교하게 타겟팅하는 방법 (81) | 2023.08.19 |
| 유사도 함수 하나로 해결하는 (개인화)추천 알고리즘 (75) | 2023.08.14 |