자연어 검색의 태동
게시판에서 제목이나 내용을 선택하고 검색하는 기능은 데이터베이스에서 특정한 단어가 포함되었는지 여부만 체크하여 조회하는 기능으로 만들어진다.
초창기 검색엔진도 이 기능을 이용하였으며 당시 웹사이트가 그리 많지 않았기 때문에 기술적인 한계는 그다지 문제가 되지 않았다. 사실 당시 검색엔진의 역할은 도메인을 일일이 타이핑하지 않게 해주는 역할이 대부분이었기 때문에 재밌게도 야후의 주요 검색어는 "구글", 그리고 구글의 주요 검색어는 "야후"였을 정도이다.
인터넷이 활성화되면서 새로운 사이트가 많이 생겨났고, 특히 게시판과 커뮤니티, 카페 등이 활성화되면서 사람들은 점점 사이트가 아닌 정보를 찾기 시작하였다. 웹사이트에 포함된 컨텐츠, 특히 게시판 등에 포함된 정보를 통합 검색하기 시작하면서 사람들은 키워드 검색에 한계를 느꼈으며, 여러 개의 단어를 붙여가면서 원하는 정보를 찾기 시작했다.
이러한 수요는 결국 자연어 검색이라는 기술의 발전으로 이어졌으며 현재와 같은 수준의 검색엔진이 나오게 되었다.
자연어 검색이 단어를 구분하는 방법
자연어 검색은 온톨로지를 기반으로 구축되었다. 온톨로지는 사물이나 개념에 대한 관계를 정의하는 기술로 자연어 검색에서는 문장에 따라 단어가 사용된 의미와 유사한 단어 등을 찾는 데 사용된다.

"사과를 저렴하게 구매하는 방법"과 "친구에게 사과하는 방법"에서 사과는 각각 다른 의미로 사용된다. 하지만, 사과라는 단어만 가지고는 어떠한 용도로 사용했는지 명확하게 구분할 수 없다. 자연어 검색은 여러 단어를 중첩하여 원하는 데이터를 좁혀 나갈 뿐 아니라, 유사한 의미까지 찾아 정확한 결과가 나오도록 발전하였다.
AI가 단어를 구분하는 방법
AI는 문장 단위로 단어를 수치화하여 좌우에 위치한 단어를 이용해 단어간의 관계를 표시한다. 온톨로지는 정확도가 높지만, 유지보수가 까다로워 신조어 등에 대응하기 어려운 반면, AI는 새로운 데이터를 스스로 학습하면서 단어의 의미를 갱신해나간다.

Cat과 Kitten은 문장의 좌우에 배치된 단어도 비슷하다. 이에 반해 Man과 Woman, 그리고 King과 Queen은 이를 수식하는 좌우의 단어들도 상반된 의미를 가지고 있다. AI는 이러한 원리를 이용하여 다차원 행렬로 단어를 수치화하고 있으며, 학습하는 문장이 많아질 수록 단어의 의미를 정교하게 찾아나간다.
최신 AI 검색 알고리즘
이제 검색엔진은 검색어가 아닌 질문을 받으려고 하고 있다. 단순히 조회된 결과를 보여주는 것이 아니라 여러가지 정보를 조합하여 원하는 답변을 생성해내려고 하고 있다. 정보를 수집하고 원하는 결과까지 만들어주는 것이 과연 검색엔진의 궁극적인 목표가 될까?
2018년 구글은 Transformer알고리즘을 이용하여 개발한 Bert를 발표하였다. 같은 Transformer알고리즘을 사용하는 GPT가 단방향으로 학습하여 이후 문장의 생성에만 초점을 맞추는 것과 달리 Bert는 양방향을 학습하여 단어가 가진 의미를 찾는데에도 목적을 가지고 있다.
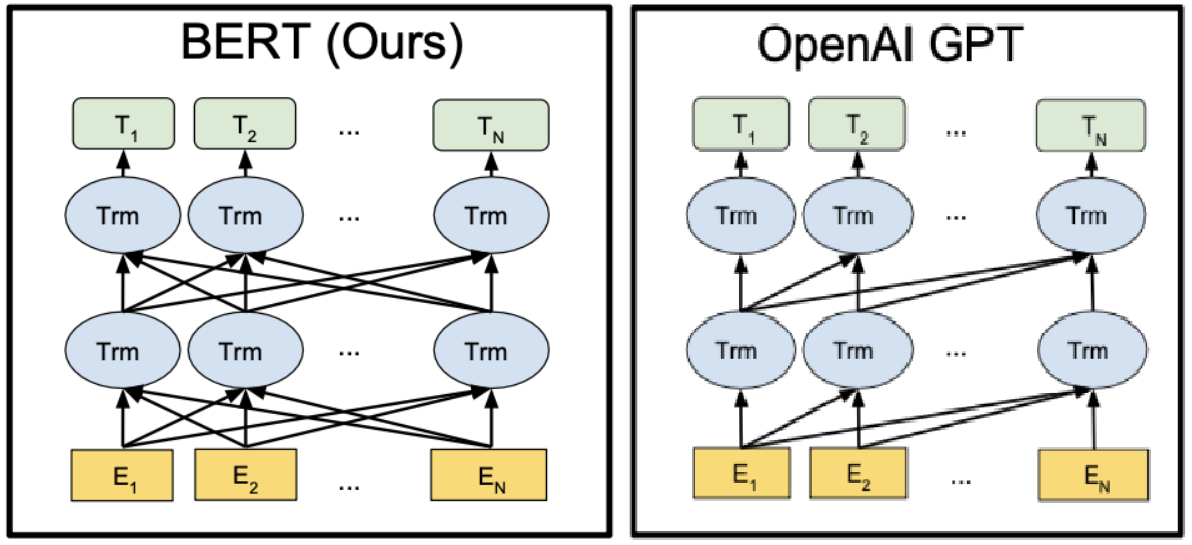
물론, 이러한 이유로 Bert가 GPT보다 우수하다고 말할 수는 없지만, 양방향 학습이 문서에 포함된 단어나 문장을 찾는 데는 최적화 되어있는 건 사실이다.
구글은 2019년부터 자사 검색엔진에 Bert를 이용하고 있으며, Bert가 공개된 이후 많은 검색엔진들이 Bert 또는 유사한 방식으로 데이터를 학습하여 검색엔진을 구축해왔다.
AI검색엔진은 새로운 검색엔진이 될 수 있을까?
이제 검색엔진은 검색어가 아닌 질문을 받으려고 하고 있다. 단순히 조회된 결과를 보여주는 것이 아니라 여러가지 정보를 조합하여 원하는 답변을 생성해내려고 하고 있다. 정보를 수집하고 원하는 결과까지 만들어주는 것이 과연 검색엔진의 궁극적인 목표가 될까?
검색엔진에 AI기술이 적용되기 시작한 건 벌써 여러 해 지났지만, 사용자가 이용하는 화면에는 큰 변화가 없었다. 특히 구글은 여전히 비슷한 디자인의 텍스트 정보를 주르륵 나열하여 사용자가 일일이 찾아내도록 하고 있다. 이러한 검색환경에 변화를 준 것은 점유율 8%로 그다지 잃을 것이 없었던 MS빙챗이었지만, 애석하게도 반년이 지난 지금 점유율에 조금의 미동도 발생하지 않았다.
사용자들은 아직 검색엔진에 질문을 던지는 게 익숙치 않아 보인다.
이제까지 검색엔진은 좀 더 명확한 정보를 찾아내도록 발전하였지만, 다음 검색엔진이 하나의 결과만 콕집어 말해주는 것으로 발전할지는 의문이다. 물론 명확한 질문을 입력하여 정리된 답변을 받는 것은 좋은 서비스지만, 무심코 TV채널을 돌리면서 재밌는 것을 찾아내듯이 백화점을 둘러보다가 맘에 드는 옷을 발견하듯이 불명확한 니즈를 가지고 여러가지 정보를 탐색하는 행동은 앞으로도 사라지진 않을 것이다.
구글은 바드에서 일부분을, 그리고 네이버는 큐라는 별도 서비스로 AI검색을 준비하고 있지만, 단순히 익숙하지 않아서 사용되지 않는 것인지 또는 기술이 미흡하여 한계가 있는 것인지, 아니면 필자가 생각하듯이 하나의 결과만 알려주는 검색은 사용자가 원하지 않을지는 앞으로 재밌게 지켜볼 수 있는 사안인 것 같다.
'쉽게 쓴 데이터·AI 지식 > AI' 카테고리의 다른 글
| FDS(이상 거래 탐지 시스템)의 동작 방식과 한계 (10) | 2024.02.22 |
|---|---|
| GPT4는 GPT3를 8개 합쳤다? 차세대 LLM의 해법이 된 MoE (95) | 2023.10.31 |
| 인간처럼 학습하는 AI로 가기 위한 멀티모달 기술 (75) | 2023.07.13 |
| OCR(광학 문자 인식)기술은 어떻게 발달하고 있을까? (81) | 2023.07.10 |
| 이미지 3장으로 알아보는 AI학습(가중치와 편향) (65) | 2023.06.28 |