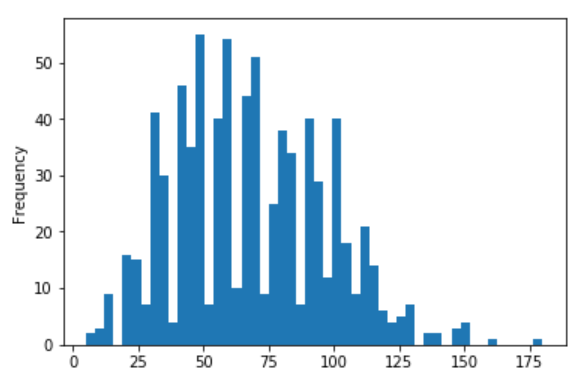
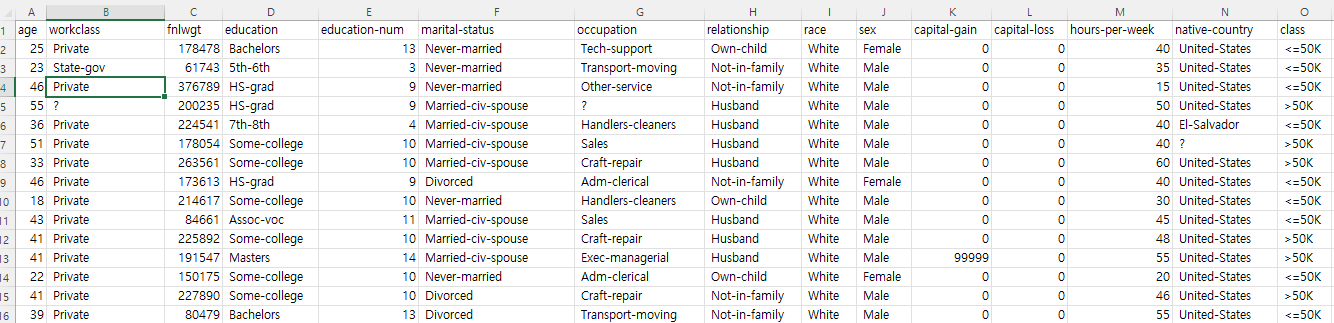
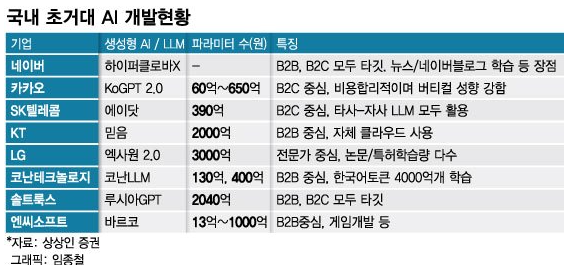
데이터 사이언티스트는 AI나 예측모델을 개발하기 위해서 가장 먼저 프로젝트의 목적에 따른 데이터의 기본 상태를 파악하고, 이에 따른 예상 결과물을 결정한 후 작업 방식과 소요시간을 예측하고 최종적으로 확보된 데이터에 대한 적합성을 판단해야 한다. 초거대 AI를 활용한 프로젝트가 많아지면서 규모가 커지고 인원과 비용도 증가함에 따라 사전 탐색과정에서 판단이 잘못되었을 경우 발생하는 손실도 커지고 있다. 서비스가 운영되고 참여자가 활동해야만 발생하는 데이터의 경우 상당한 수집 시간이 필요하며, 외부에서 구입할 경우에도 비식별처리와 전처리에 오랜 시간이 소요되기 때문에 데이터에 대한 프로젝트 초기에 이루어지는 데이터 적합성 판단은 빠르고 정확해야만 한다. 데이터 탐색의 기본 단계 데이터를 탐색할 때는 기본적으..