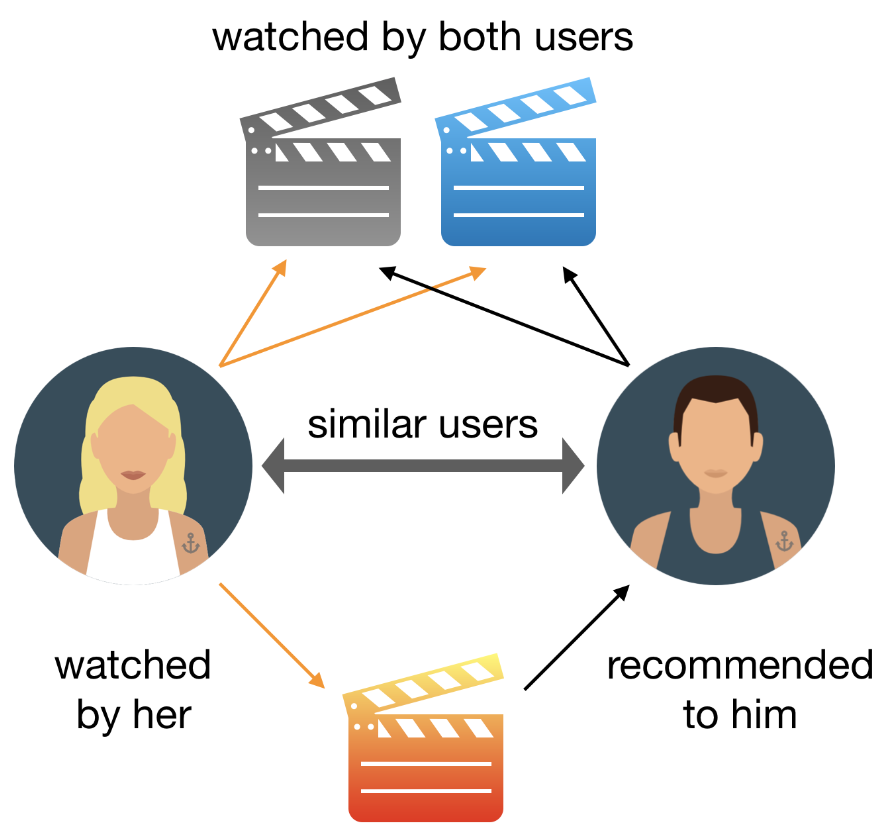
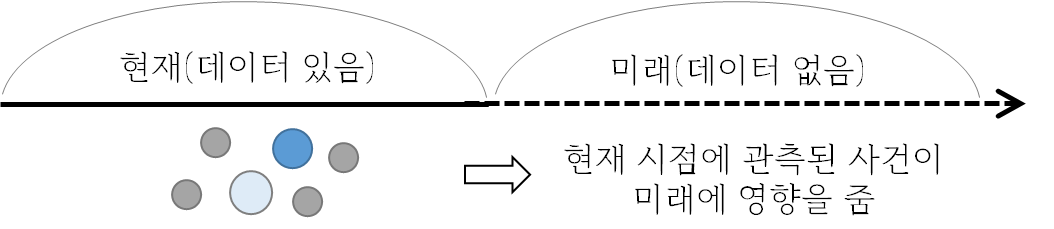
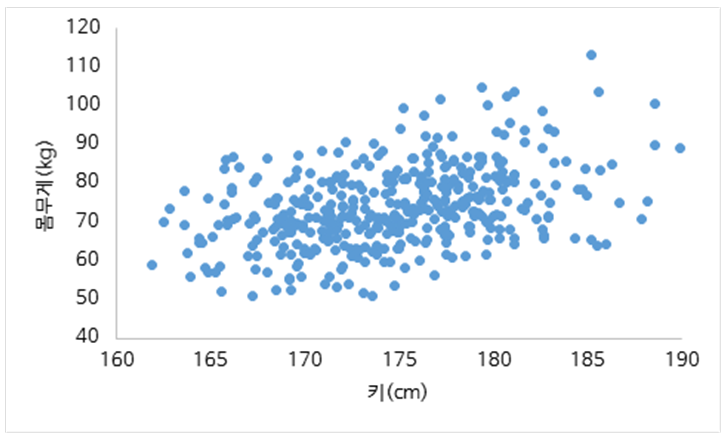
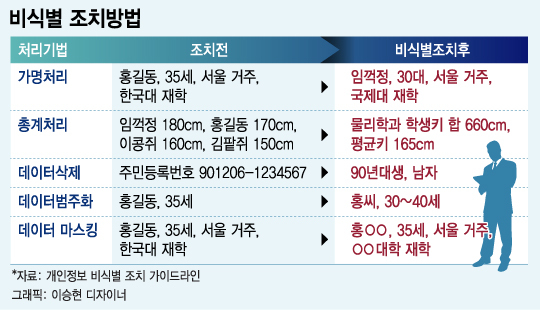
데이터 라벨링 정의 데이터 라벨링은 데이터에 의미있는 정보(레이블)를 부여하여, AI학습을 위한 데이터셋을 만드는 과정이다. 라벨링된 데이터는 정답을 예측하는 지도 학습(Supervised Learning)에 주로 이용된다. 이미지, 음성, 텍스트 등 다양한 유형의 데이터에서 개체를 분류하거나 정보를 입력하는 데 적용된다. 라벨링에 사용되는 도구는 Labelbox, RectLabel, VGG Image Annotator 등이 있으며, 클라우드 서비스 등에서도 제공하고 있다. 일부 라벨링 작업은 정확도가 떨어지더라도 자동화 도구(오토 라벨링 툴)를 이용할 수 있다. 라벨링 정확도를 높이기 위해서 품질 관리 및 검토 프로세스를 포함해야 한다. 개인정보가 포함된 데이터를 라벨링할 때는 데이터 유출에 대한 보호..